Factor graphs¶
Introduction¶
Graphs - nodes/vertices, edges
- directed/undirected
- Neighbors (vertices connected with edges)Factor graphs:
- Variables nodes (unknowns)
- Factor nodes (known constraints such as priors, odomtery or measurements)
- Edges (connects factors to variables. No meaning)
- Bipartite (variable-factor-variable)Variable interaction graphs
- Factor graph converted to plain undirected graph over variables only
(factors removed as they sit on the edges you just have to remove the black dots)
- Connect two variables that have appear together in a factor graphPaths and cycles
- Sequence of edges connecting nodes is a path
- Path that starts and ends at the same node is a cycle. x1-x2-l1-x1Clique
- Set of nodes where every pair is connected by an edge (fully connected subgraph)
x1-x2-l1 is a clique (a 3-clique)
Maximnal Clique
A clique is maximal if you cant add another node and have a clique. For eg. adding x3
to {x1,x2,l1} because x3 isnt connected to x1 or l1. So {x1,x2,l1} is a maximal clique
Basically if we see any subset of a clique is a clique as well. Hence the biggest set
that contains all these cliques is maximalFrontal variables and Separators
p(x1|x2,l1) has x1 as frontal variable and x2, l1 as separator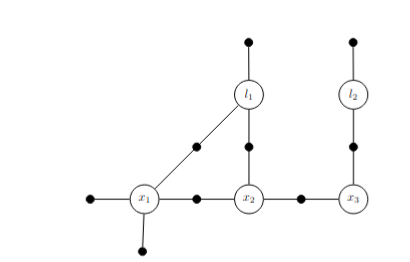
Factor graph connecting x1, x2, x3 odomtery poses with two landmarks l1 and l2
Factor graph formation for the estimation problem is MAP inference. You are given measurements/data and you have to find p(x|z) which means finding the most probable parameters/variables given your data/measurements.
where p(Z) can be omitted since it does not depend on X.
When working with factor graphs factors are proportional to the above probabilities as can be seen from the below equation. The product of the factors in a factor graph defines a global function which is a measure of joint probability p(X|Z). The factor values need only be proportional to corresponding probability densities: any normalization constant that do not depend on the state variables may be omitted without consequence.
The first assumption to make the problem tractable is gaussian noise in measurements, odometry and priors.
The measurement function above in most cases are non linear. To make this tractable we linearize it and convert the minimization problem on into a minimization problem on
where the last term is obtained by stacking individual factor jacobians and residuals in a big matrix.
This problem needs to be formulated and solved for non-linear optimization at each iteration with the first iteration getting linearized at the initial estimate and each successive linearization happening at the current best estimate. The methods to solve a non linear problem is:
Steepest descent: Basically gradient descent. Have to choose step size wisely.
Gauss newton: Gauss newton approximates hessian by and solves
The objective function should be nearly quadratic with a good initial estimate for GN to work.
LM:
Note that for we obtain GN, and for large we approximately obtain , an update in the negative gradient direction of the cost function. Hence LM can be seen to blend naturally between the GN and SD methods.
In LM, lambda is heuristically changed when an update is rejected(its made higher) so that smaller steps are made. If update passes then lambda is decreased to make larger steps.
approximates the hessian. If surface is flat then hessian eigenvalues are small which means diagonal of is small. Hence del_lm = is large.
Batch Inference¶
There are two ways to solve this optimization problem specifically the problem (since gradient descent part in LM and SD is computationally easieras it does not include inverses):
Using sparse matrix factorization such as QR and Cholesky decomposition. This approach runs cholesky or QR to solve for updates in each iteration or non linear optimization. We dont compute Q and R matrices for [A|b] specifically however we use householders reflection to get R directly as in:
which can be backsubstituted to get values of each .
Cholesky also gives the same R as in
Since the system is sparse, how the column ordering of or is chosen effects the compute. All orders produce the same MAP solution but the variable order determines the fillin of matrix factors R (both while using QR or cholesky). Heuristics like COLAMD is used to reduce the fill-ins and factorize the matrix efficiently.
Using graphical models such as factor graphs. See Elimination section for this below. The above approaches are useful since SLAM problems are sparse in anture.
Approach 1 is mostly used for linear factors. Factor graphs can be used for non linear factors as well.
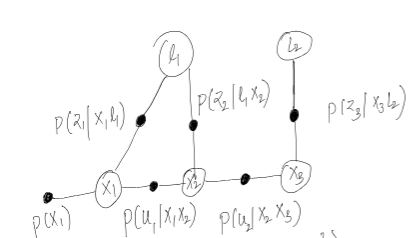
This seems to be the probabilities that the graph represents. p(z|x,l) is straightforward basically prob of measurement given pose and landmark where the measurement was taken. p(u|x1,x2) can be thought of as odometry measurement which was taken between x1 and x2 poses. I have not included priorson landmarks but that can be added as well.
For example for a graph like:
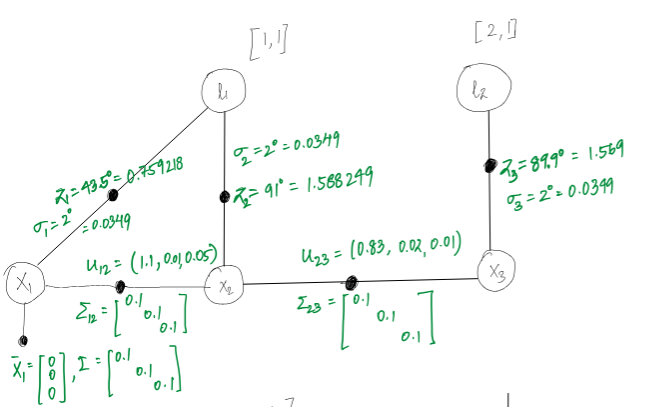
Considering an environment modelling like below:

Using the above values for the poses and measurements we have:

Objective

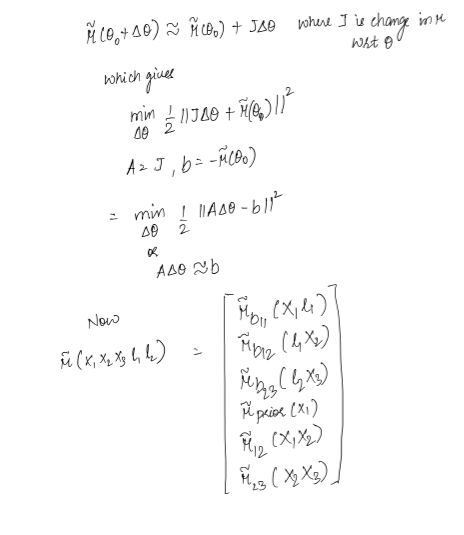
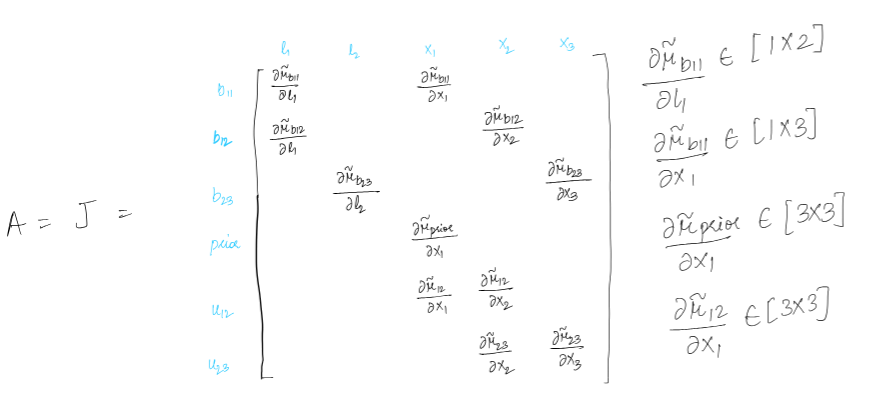
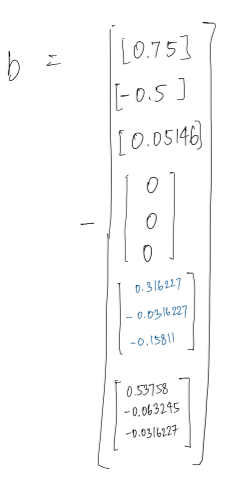
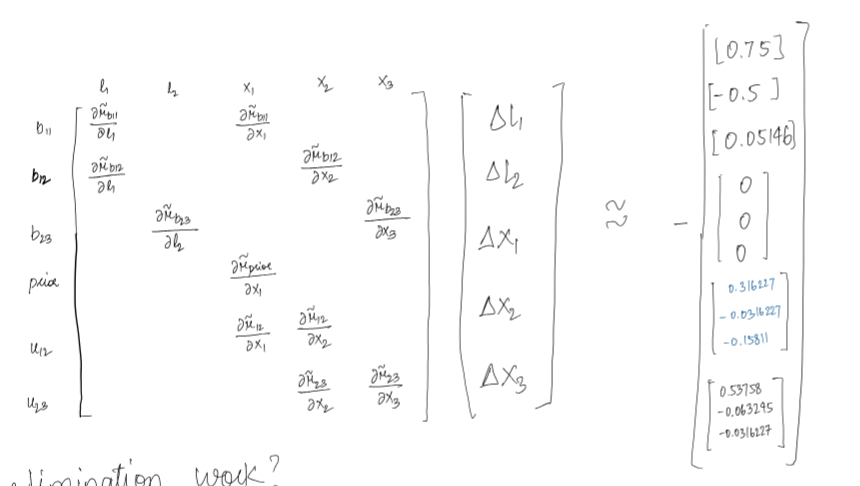
Jacobian of the factors is sparse and touches the variables involved in the factor. Hence A is sparse which means information matrix A transpose A is sparse as well.
Elimination
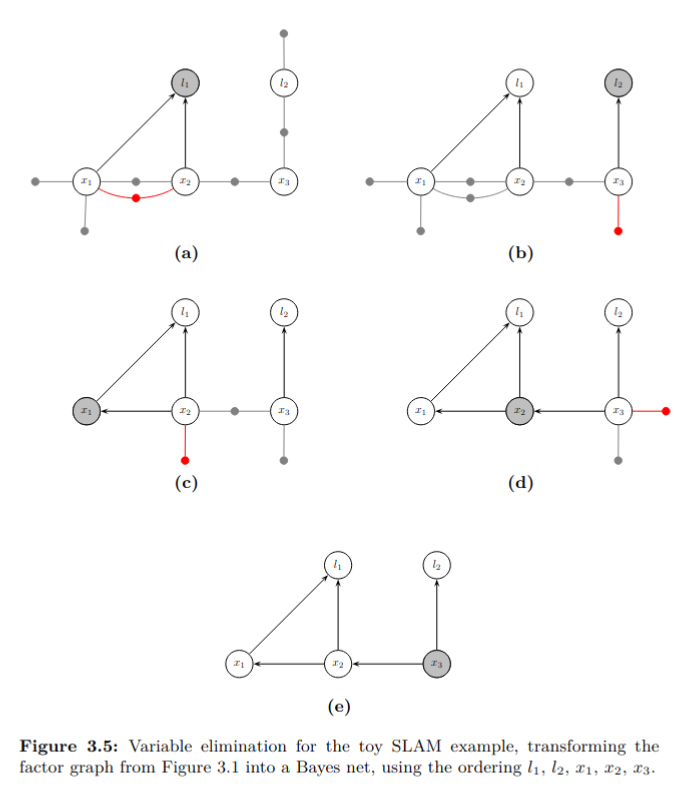
A factor graph is converted into a Bayes net first. This removes the constraints and gives us a graph with only unknowns in it.
To eliminate a single variable given a partially eliminated factor graph , we first remove all factors that are adjacent to and multiply them into the product factor . We then factorize into a conditional distribution on the eliminated variable , and a new factor on the separator :
The above equation is something I havent been able to understand. Why is this true?
The entire factorization from to is seen as a succession of n local factorization steps. When eliminating the last variable the separator will be empty, and the conditional produced will simply be a prior on .

In the case of linear measurement functions and additive normally distributed noise, the elimination algorithm is equivalent to sparse matrix factorization. Both sparse Cholesky and QR factorization are a special case of the general algorithm.
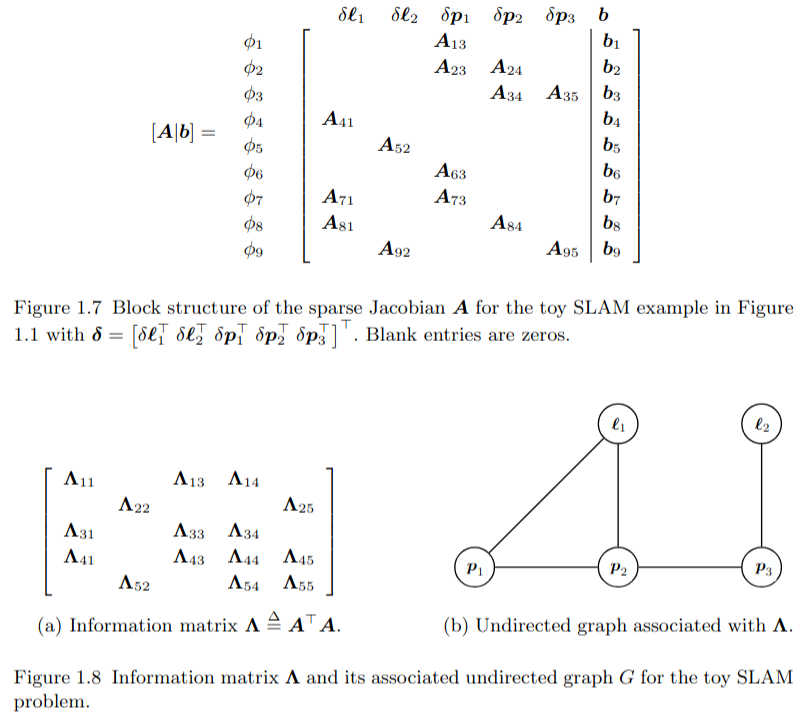
The elimination algorithm proceeds one variable at a time. Following Algorithm 3.2, for every variable we remove all factors adjacent to , and form the intermediate product factor . This can be done by accumulating all the matrices into a new, larger block-matrix , as we can write
where the new RHS vector stacks all .
Example. Consider eliminating the variable in the toy example. The adjacent factors are , and , in turn inducing the separator . The product factor is then equal to
with
Factorizing the product can be done in several different ways. Here we discuss the QR variant, as it more directly connects to the linearized factors. In particular, the augmented matrix corresponding to the product factor can be rewritten using partial QR-factorization as follows:
where is an upper-triangular matrix. This allows us to factor as follows:
where we used the fact that the rotation matrix does not alter the value of the norms involved.The entire elimination algorithm, using partial QR to eliminate a single variable, is equivalent to sparse QR factorization.
This Gaussian factor graph corresponding to the linearized nonlinear problem is transformed by elimination into the density given by the now familiar Bayes net factorization:
In both QR and Cholesky variants, the conditional densities are given by
which is a linear-Gaussian density on the eliminated variable . Indeed, we have
where the mean depends linearly on the separator , and the covariance matrix is given by . Hence, the normalization constant .
After the elimination step is complete, back-substitution is used to obtain the MAP estimate of each variable.

Reverse order is just since last eliminated variable has no separator and so on.
Incremental Inference¶
The above two approaches for MAP inference: matrix factorization and Bayes net inference are both useful in batch optimization where you know the data in advance. If you are working in a incremental setting where you are receiving data in real-time, then you can incrementally update the matrix factorization for linear factors or Bayes net for non-linear factors.
For our linear gaussian factor case , we have the objective function as
where is a constant that reflects the sum of squared residuals of the least-squares problem.
When a new measurement arrives, instead of updating and refactoring a new system from scratch, we have the option to modify the previous factorization directly by QR-updating. Let us assume that is formed by adding a single new measurement row with corresponding RHS element , i.e.,
Then a QR update proceeds as follows: adding to the previous factor and the new scalar element to the previous RHS yields a new system that is not yet in the correct factorized form:
A series of Givens rotations are applied to zero out the new row, starting from the left-most nonzero entry and resulting in an upper triangular matrix that contains the updated factor
After all is said and done, the incremental factorization is equivalent to rewriting the updated objective without re-factoring , as desired:
where is a constant that reflects the sum of squared residuals of the least-squares problem.
When a new measurement arrives, instead of updating and refactoring a new system from scratch, we have the option to modify the previous factorization directly by QR-updating. Let us assume that is formed by adding a single new measurement row with corresponding RHS element , i.e.,
Then a QR update proceeds as follows: adding to the previous factor and the new scalar element to the previous RHS yields a new system that is not yet in the correct factorized form:
A series of Givens rotations are applied to zero out the new row, starting from the left-most nonzero entry and resulting in an upper triangular matrix that contains the updated factor
After all is said and done, the incremental factorization is equivalent to rewriting the updated objective without re-factoring , as desired:
Two things to note here:
When we convert A to R (upper triangular) using QR, if we have A as mxn then R only has top nxn populated and bottom rows are 0. Hence you would notice the notation
When you do givens rotation check how is still orthogonal after adding 1. Because of that check how and directly append into and .
There was a note saying you can non-zero out few entries in bottom row when you do givens rotation. Thats an artifact of givens. What givens does is that it takes the new row let say n+1 and in that i column. To zero out i column entry it mixes that row and i row in the matrix using 2D rotations.
Since ith column already has [0,i) column entries zeroed out the already processed entries of last row dont alter. Only the entries who are to be processed later are affected which can be easily rotated when they are to be.
Approach 2:¶
The desire of generalizing incremental inference to nonlinear problems motivates the introduction of the Bayes tree graphical model. Matrix factorization operates on linear systems, but most inference problems in robotics of practical interest are nonlinear, including SLAM. In the incremental matrix factorization story it is far from obvious how re-linearization can be performed incrementally without refactoring the complete matrix. To overcome this problem we investigate inference in graphical models, and introduce a new graphical model, the Bayes tree.
The main reason we are going for Bayes tree is the efficiency of inference in tree structured graphs. In case of Bayes net and factor graphs, cycles are present and inference is not trivial. Hence we follow a two step process of first converting the factor graph to a Bayes net using elimination and then converting the Bayes net to a Bayes tree. The Bayes net we get after elimination on factor graph has a special property; it is chordal which helps in converting it to a Bayes tree.
By identifying cliques (groups of fully connected variables) in this chordal graph, the Bayes net may be rewritten as a Bayes tree.
More formally, a Bayes tree is a directed tree where the nodes represent cliques of the underlying chordal Bayes net. In particular, we define one conditional density per node, with the separator as the intersection of the clique and its parent clique . The frontal variables are the remaining variables, i.e. . We write . The following expression gives the joint density on the variables defined by a Bayes tree:
For the root the separator is empty, i.e., it is a simple prior on the root variables. The way Bayes trees are defined, the separator is always a subset of parent clique and hence directed edges mean conditioning.